 Jun 05,2026
Jun 05,2026 
We now offer more than 14.326 million predictive personas in each of 23+ countries, and our demographics selector accepts plain-English audience descriptions instead of stacked filter menus. The two updates in this release target the two places where recruitment-based research fails most often, geographic coverage and audience definition. A team that needed feedback from buyers in Japan or Brazil last quarter faced expat-heavy panels and 2-week recruitment windows. That same comparison can now run against locally modeled personas the same day.
Country-Level Depth in the Persona Database
Research panels concentrate where their participants live, and that concentration is overwhelmingly American and British, which is why per-country depth matters more in this release than the raw database size. Prolific, one of the most widely used participant pools, offers representative samples for the UK and US only. A researcher who buys access to respondents in Japan usually gets foreigners living in Japan or Japanese citizens living abroad, since the major testing tools never shipped in Japanese and foreign residents make up under 2% of the country’s population.
Cost compounds the coverage problem. International participants cost at least twice the US rate per completed session, and recruitment firms add $100 to $300 per qualified person. A study that crosses borders also picks up translated consent forms, back-translated responses, and session calls at 6 a.m. to catch a participant in another hemisphere.
Local depth determines what a market test can catch. In one Brazil study, a single Afro-Brazilian participant was the only person to flag imagery that depicted their ethnic group negatively, a finding no US-based session would have produced. We model more than 14.326 million personas inside each country rather than sampling every region from one global pool, so a checkout flow compared across 5 markets is tested against each market’s own population at equal depth.
Natural-Language Audience Selection
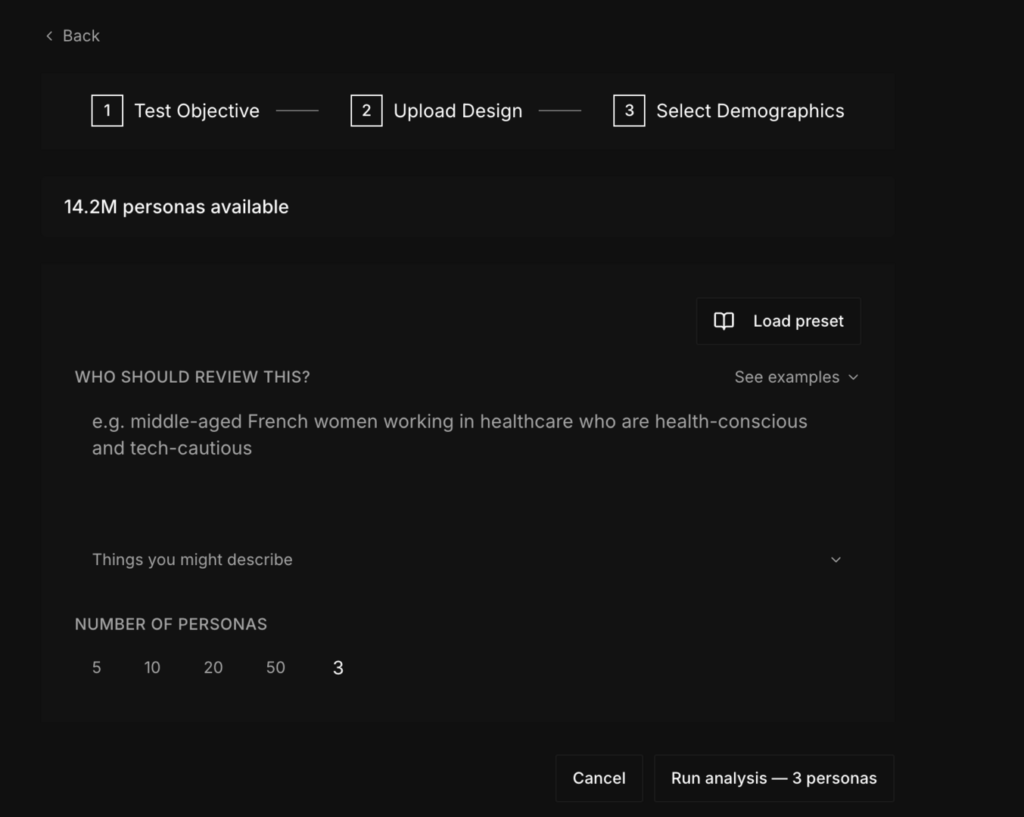
Until this release, defining an audience on our platform meant stacking filter menus, with age bands, income brackets, education, geography, and 1,700+ job titles, and availability counts updating as each filter narrowed the pool. Menus handle common segments without trouble, and they break down the moment a team needs an intersection the taxonomy never anticipated, such as rural pharmacists who replaced their practice-management software within the past year.
Recruitment platforms patch that gap with screener surveys, and screeners are easy to game. Longtime panelists learn that the first few answers decide who gets paid. One published test asked panel respondents about drugs that do not exist, and they claimed familiarity at measurably higher rates than fresh respondents recruited outside the panel. Researchers kept using filter menus and screeners because nothing better existed for defining a sample, and the fraud-detection tooling now sold alongside panels is a measure of how unreliable that setup is.
The update replaces filters and screeners with a typed description. A researcher writes out the target audience in plain English, and our Intelligent Audience Engine finds the matching personas across the database. A one-sentence description works as a sampling instruction because of the detail already built into each persona. Each persona is built with professional context, risk tolerance, decision speed, and life circumstances, so the rural-pharmacist description resolves to profiles whose records support it.
Practical Effects on Research Workflows
Per-run pricing does not change as the scope widens. A typical run uses 8 to 12 personas and returns scored feedback in 10 to 30 minutes. At the 10-persona size, that costs roughly $23.90 to $29.90. Comparing a pricing page across 5 countries becomes an afternoon of runs, work that previously meant a quarter of agency coordination and $10,000-to-$20,000 study phases. Teams previously answered that comparison for one market and guessed for the rest.
None of this replaces sessions with real people. Synthetic feedback can reproduce a real failure on one task and miss real friction on another, which is why simulated testing fits discovery work while final decisions belong to live participants. We take the same position about our own platform, which we built to accelerate and augment research. Our case study reports 89.78% agreement between persona predictions and real-user feedback, and that is our own measurement rather than an independent benchmark. The workflow that respects both sides pairs fast persona rounds with human validation at the decision point.
Conclusion
Coverage and definition were the constraints that kept early research narrow, and this release addresses both at once. Country-level persona depth across 23+ markets makes international comparison affordable inside routine testing budgets. A selector that takes a typed description lets teams define segments in the words a product manager would use in a planning meeting, with no filter menus in the path. We built this update for the audiences that were too expensive to reach and the segments that never fit a menu.